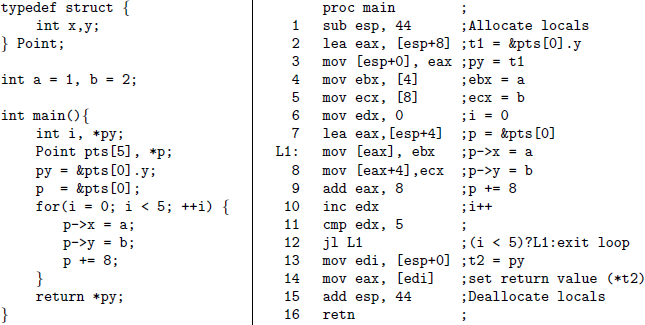
One of BAP’s biggest omissions is that it does not do CFG/code
recovery. CFG recovery (or code recovery) is the process of finding
what parts of an executable are code. If you have ever used IDA Pro,
when you first load a file, the initial analysis phase is actually
performing CFG recovery. For this, IDA Pro uses a combination of
recursive disassembly (if address a is code and has jmp 1234, then
1234 must be code too) and heuristics like looking for push %ebp;
mov %esp, %ebp.
A third approach to CFG recovery, besides recursive disassembly and
heuristics, is abstract interpretation. Abstract interpretation is a
method for analyzing programs in a sound way. One abstract
interpretation algorithm for recovering CFGs is called Value Set Analysis, or VSA for short. VSA works by overapproximating the values of variables by using strided intervals. A strided interval is a combination of an interval, like [1,3], which represents the set {1,2,3}, and an interval, which represents the step between each element. For instance, the strided interval 5[0,9] represents the set {0,4,9}. The idea in VSA is that once you can approximate program values in this way, you can then reason about (resolve) indirect jumps, and thus recover the CFG.
BAP has a partial implementation of VSA, but it needs some re-design
before we can use it for CFG recovery. First, we need to change the
type of CFG edges. Right now, CFG edges are of type bool option,
since an edge can be an unconditional jump (None), or be the taken
or non-taken edge of a conditional jump (Some true or Some false).
However, we need more expressive edges for two reasons. First, we
need to represent information about recovered indirect jumps. For
instance, we might find that jmp (%eax) goes to address 10 when %eax
is 30, and to address 20 when %eax is 100. Obviously we can’t
represent this using true and false; we need expression types. The
second reason we need more expressive edges is that some abstract
interpretation algorithms, like VSA, are defined for both program
statements and edge conditions.
This is best understood with an example. In the above program,
it’s easy to see that x can only contain the values {0,1,2} coming
into BB 1. We know this, because x starts with value 0, and if it
had a value above 3, control would transfer to BB 2. VSA can actually
determine this. BAP’s VSA does not take edge conditions into account
(after all, edges have no conditions!), and so BAP would be forced to
conclude that the range of x is [0, ∞] coming into BB 1.
Okay, so we want to add conditions to CFG edges. BAP’s VSA
implementation uses the Single Static Assignment (SSA) form, so let’s
convert our program to that and see what it looks like.
What’s this temp variable? Well, it’s a temporary variable introduced
because BAP’s SSA form is three address code (TAC). TAC ensures that each expression has no subexpressions. Instead, subexpressions must be computed with separate assignments. This makes some analyses simpler. For instance, Strongly
Connected Component Value Numbering (SCCVN) can easily identify common
subexpressions, since each subexpression gets its own assignment.
Unfortunately, TAC comes back to bite us in VSA. The edge temp =
false does not convey any information about x to VSA, since VSA can
only relate edge conditions to data values syntactically, that is to
temp. This is the major difference between abstract interpretation
and a symbolic analysis like symbolic execution. Symbolic analysis
can reason about the effect of an edge condition on a data value with
symbolic constraints. Abstract interpretation typically does not
involve constraint solving, and thus VSA does not know how an edge
condition affects a data value in the general case.
So, to make a long story short, I am going to adjust BAP’s SSA
representation so that TAC is not enforced by the type system.
Instead, we’ll have an option to lift to TAC, which we will use with
SCCVN. VSA, however, will use the non-TAC version of SSA. Once VSA
is fixed, it should be straight-forward to use the resulting
information to do CFG recovery.