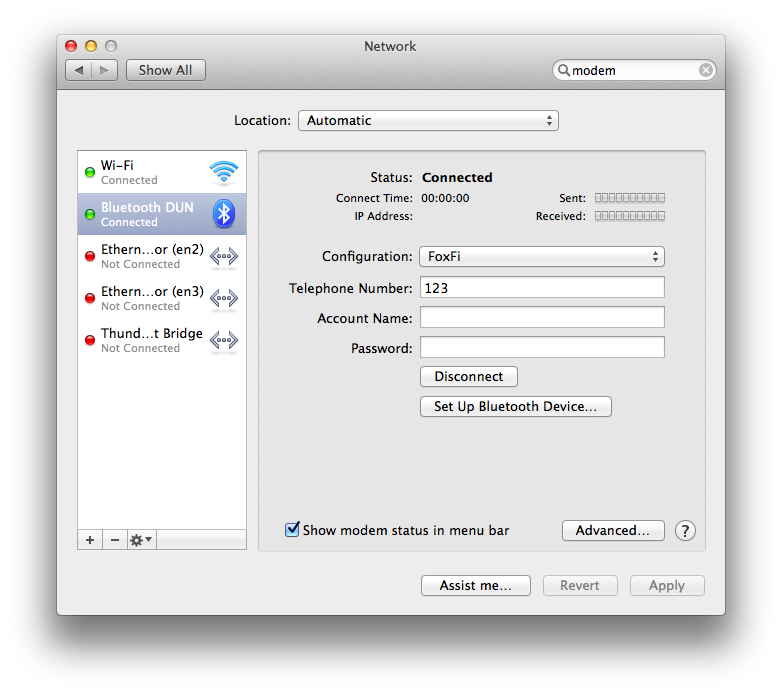
In theory, I can work anywhere with my backpack. I just tether my
laptop over bluetooth and I’m good to go. In practice, I do this
infrequently enough that bluetooth breaks for some reason, and I spend
an hour trying to fix my tethering setup, rather than completing an
hour of work. Today was no exception.
I spent an hour trying to get my MacBook Air, which runs OS X 10.9.2,
tethered over bluetooth to FoxFi/PdaNet. The last time I connected
was before I had Mavericks, and of course the connection didn’t work.
The connection displayed as connected, but the connection duration
stayed at 0 seconds, and no IP address was shown. More importantly,
there was no connectivity!
Turning on verbose PPP logging and peeking at ppp.log revealed this:
Fri Feb 28 17:47:26 2014 : Serial connection established.
Fri Feb 28 17:47:26 2014 : using link 0
Fri Feb 28 17:47:26 2014 : Using interface ppp0
Fri Feb 28 17:47:26 2014 : Connect: ppp0 <--> /dev/cu.Bluetooth-Modem
Fri Feb 28 17:47:27 2014 : sent [LCP ConfReq id=0x1 <asyncmap 0x0> <magic 0x1c48b84f> <pcomp> <accomp>]
Fri Feb 28 17:47:27 2014 : rcvd [LCP ConfRej id=0x1 <magic 0x1c48b84f>]
Fri Feb 28 17:47:27 2014 : sent [LCP ConfReq id=0x2 <asyncmap 0x0> <pcomp> <accomp>]
Fri Feb 28 17:47:27 2014 : rcvd [LCP ConfAck id=0x2 <asyncmap 0x0> <pcomp> <accomp>]
Fri Feb 28 17:47:27 2014 : rcvd [LCP ConfReq id=0x1c <asyncmap 0x0> <pcomp> <accomp>]
Fri Feb 28 17:47:27 2014 : lcp_reqci: returning CONFACK.
Fri Feb 28 17:47:27 2014 : sent [LCP ConfAck id=0x1c <asyncmap 0x0> <pcomp> <accomp>]
Fri Feb 28 17:47:27 2014 : sent [IPCP ConfReq id=0x1 <compress VJ 0f 01> <addr 0.0.0.0> <ms-dns1 0.0.0.0> <ms-dns3 0.0.0.0>]
Fri Feb 28 17:47:27 2014 : sent [IPV6CP ConfReq id=0x1 <addr fe80::6aa8:6dff:fe02:81da>]
Fri Feb 28 17:47:28 2014 : rcvd [IPCP ConfRej id=0x1 <compress VJ 0f 01>]
Fri Feb 28 17:47:28 2014 : sent [IPCP ConfReq id=0x2 <addr 0.0.0.0> <ms-dns1 0.0.0.0> <ms-dns3 0.0.0.0>]
Fri Feb 28 17:47:28 2014 : rcvd [IPCP ConfReq id=0x1c <addr 192.168.19.2>]
Fri Feb 28 17:47:28 2014 : ipcp: returning Configure-ACK
Fri Feb 28 17:47:28 2014 : sent [IPCP ConfAck id=0x1c <addr 192.168.19.2>]
Fri Feb 28 17:47:28 2014 : rcvd [IPV6CP ConfRej id=0x1 <addr fe80::6aa8:6dff:fe02:81da>]
Fri Feb 28 17:47:28 2014 : sent [IPV6CP ConfReq id=0x2]
Fri Feb 28 17:47:28 2014 : rcvd [IPCP ConfNak id=0x2 <addr 192.168.19.2> <ms-dns1 8.8.8.8> <ms-dns3 8.8.4.4>]
Fri Feb 28 17:47:28 2014 : sent [IPCP ConfReq id=0x3 <addr 192.168.19.2> <ms-dns1 8.8.8.8> <ms-dns3 8.8.4.4>]
Fri Feb 28 17:47:28 2014 : rcvd [IPV6CP ConfAck id=0x2]
Fri Feb 28 17:47:28 2014 : rcvd [IPCP ConfAck id=0x3 <addr 192.168.19.2> <ms-dns1 8.8.8.8> <ms-dns3 8.8.4.4>]
Fri Feb 28 17:47:28 2014 : ipcp: up
Fri Feb 28 17:47:28 2014 : local IP address 192.168.19.2
Fri Feb 28 17:47:28 2014 : remote IP address 192.168.19.2
Fri Feb 28 17:47:28 2014 : primary DNS address 8.8.8.8
Fri Feb 28 17:47:28 2014 : secondary DNS address 8.8.4.4
Fri Feb 28 17:47:31 2014 : sent [IPV6CP ConfReq id=0x2]
Fri Feb 28 17:47:31 2014 : rcvd [IPV6CP ConfAck id=0x2]
Fri Feb 28 17:47:34 2014 : sent [IPV6CP ConfReq id=0x2]
Fri Feb 28 17:47:34 2014 : rcvd [IPV6CP ConfAck id=0x2]
Fri Feb 28 17:47:37 2014 : sent [IPV6CP ConfReq id=0x2]
Fri Feb 28 17:47:37 2014 : rcvd [IPV6CP ConfAck id=0x2]
Fri Feb 28 17:47:40 2014 : sent [IPV6CP ConfReq id=0x2]
Fri Feb 28 17:47:40 2014 : rcvd [IPV6CP ConfAck id=0x2]
Fri Feb 28 17:47:43 2014 : sent [IPV6CP ConfReq id=0x2]
Fri Feb 28 17:47:43 2014 : rcvd [IPV6CP ConfAck id=0x2]
Fri Feb 28 17:47:46 2014 : sent [IPV6CP ConfReq id=0x2]
Fri Feb 28 17:47:46 2014 : rcvd [IPV6CP ConfAck id=0x2]
Fri Feb 28 17:47:49 2014 : sent [IPV6CP ConfReq id=0x2]
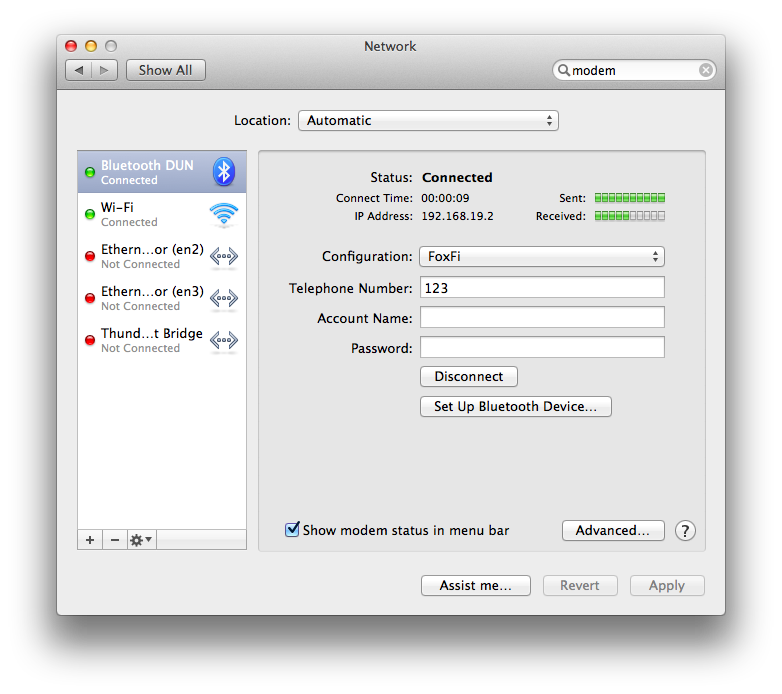
I’m not a PPP wizard, but it looks to me like something is wrong with the IPV6 autoconfiguration. I turned off IPV6 on my Bluetooth DUN interface via:
1
networksetup -setv6off "Bluetooth DUN"
And sure enough, I got a connection:
I hope this helps somewhat else. I have no idea why Apple’s PPP
implementation would not do something, like, say, time out. In fact,
the pppd man page even lists a ipv6cp-max-configure n option, which
is described as:
1
Set the maximum number of IPv6CP configure-request transmissions to n (default 10).
This suggests to me that after 10 IPV6CP packets the connection should
work. But this doesn’t happen. I don’t really have time to
investigate why.
I spend a lot of my time building and evaluating implementations for
research papers. Over time, I’ve built a strategy for running
evaluations. I just uploaded a project to github with a skeleton for
performing evaluations how I do. The description is available
here, and the github project is here.
If you spend enough time around me, you will probably hear me extol
the virtues of statically typed languages such as ML or Haskell.
Statically typed languages are great, because they find so many bugs
before you even run your program. In fact, a good friend of mine
jokes about OCaml program that “If it compiles it is correct!” This
is not true, of course. OCaml does not check that your algorithm’s
logic is correct, for instance.
Yesterday I encountered what I would consider a “type bug” in OCaml.
There was human error involved, but I was still surprised that such a
bug is possible in a type-checked program.
In BAP, we have a utility function, Util.timeout, which performs a
computation, and if it takes too long, aborts it and raises an
exception. The timeout function has type: int -> ('a -> 'b) -> 'a
-> 'b, or in plain english, takes the number of seconds, a function
f to execute, and a value x such that f x is computed.
The problem we observed was that timeouts were simply not working: the
code would run for a very long time. The timeout function was being
called, though, and at first glance I thought it looked fine:
Util.timeout 3 Asmir_disasm.vsa_at p addrvsa_at takes two
arguments, so this makes some intuitive sense. But a closer look
reveals that we are psssing 4 arguments to Util.timeout, and it
only takes 3 — How is this possible?
The problem is that timeout is polymorphic, and the type inference
engine decided that 'a = Asmir.asmprogram and 'b = Type.addr ->
Cfg.AST.G.t * unit, or in plain english: we want to partially
evaluate the vsa_at function on only one argument, and timeout if
that takes too long. Unfortunately, partial evaluation is usually
very fast. The slowdown occurs when the extra argument, addr is
then consumed by this partially evaluated function. Another way of
viewing this is that OCaml thinks we wanted to do (Util.timeout 3
Asmir_disasm.vsa_at p) addr.
The solution is simply to force the partial evaluation to occur
earlier, i.e., Util.timeout 3 (Asmir_disasm.vsa_at p) addr. I think
that such a bug should at least trigger a warning, or maybe even
require explicit parenthesization in such cases to denote currying is
intentionally being applied. However, the consensus at lunch was that
I am wrong, and the programmer should not make such mistakes. But
isn’t the point of static type checking to find dumb mistakes?
The use of OCaml in BAP has both positives and negatives. OCaml’s
pattern matching is a wonderful fit for binary analysis. However,
very few people know OCaml, and thus few people can understand or
modify BAP’s source code. Although you can do some nifty things
without digging into BAP’s source code, this only touches the surface
of BAP’s capabilities.
Today I added a feature which I hope will bring BAP to the masses —
well, at least to the masses of security people who want to use BAP
but haven’t because they do not use OCaml. This feature should allow
users to easily read and analyze the BAP IL in the comfort of their
favorite programming language, whatever that might be.
BAP has always had a robust pretty printer and parsing mechanism which
could, in theory, be parsed by other languages. But honestly — who
wants to build a parser to parse the BAP IL? It’s annoying, and I
doubt anyone has gone through the trouble of doing it. The new
feature I added gives users the ability to serialize the BAP IL to a
number of formats, including protobuf, XML, JSON, and Piqi. If your
programming language doesn’t have libraries to parse one of these
formats, it probably isn’t worth using.
Let’s take a look at some examples. Here’s some BAP IL:
Hopefully this will encourage some new people to use and contribute to
BAP. Adding support for new instructions isn’t that hard, even for
people that don’t know OCaml! This serialization will be in BAP 0.7,
which will be released in a few days.
Q
is the automated return oriented programming system (ROP) that I
developed with my colleague, Thanassis Avgerinos. The basic idea
behind ROP is to find small code fragments that do something useful in
a binary that you are attacking. These code fragments are called
gadgets. (Do you get the reference to Q now?) Later, the gadgets are
strung together to accomplish something even more useful. (Hint: It
can be Turing-complete.) ROP can be used to bypass program defenses
such as Data Execution Prevention.
I’m not doing much personal work with Q these days, but it has become
fairly popular as a tool for evaluating proposed ROP defenses. I just
added a new option for such an evaluation. The new option forces Q to
only consider gadgets at specified addresses. Naturally, to make sure
it works, I specified a random gadget address, 0x80492d9, and checked
the output:
123456789101112131415161718192021
Printing Noop gadgets: 0
Printing Jumps gadgets: 0
Printing JumpConsts gadgets: 1
SET: JumpConst {} Other +0 @0 (Addrset: @0 ) [This gadget is fake.]
Printing Move gadgets: 1
SET: MoveReg R_EBX_6:u32 -> R_EAX_5:u32 { R_EAX_5:u32 R_EBX_6:u32 R_EDI_3:u32 R_ESP_1:u32} Ret +c @80492d9 (Addrset: @80492d9 @80492da @80492db @80492dc @80492dd ) [; mov %ebx,%eax; pop %ebx; pop %edi; ret ]
Printing LoadConst gadgets: 3
SET: LoadConst const(+0) -> R_EAX_5:u32 { R_EAX_5:u32 R_EBX_6:u32 R_EDI_3:u32 R_ESP_1:u32} Ret Ret +c +c @80492d9 @80492d9 (Addrset: @80492d9 @80492da @80492db @80492dc @80492dd ) [; mov %ebx,%eax; pop %ebx; pop %edi; ret COMBINED; mov %ebx,%eax; pop %ebx; pop %edi; ret ]
SET: LoadConst const(+0) -> R_EBX_6:u32 { R_EAX_5:u32 R_EBX_6:u32 R_EDI_3:u32 R_ESP_1:u32} Ret +c @80492d9 (Addrset: @80492d9 @80492da @80492db @80492dc @80492dd ) [; mov %ebx,%eax; pop %ebx; pop %edi; ret ]
SET: LoadConst const(+4) -> R_EDI_3:u32 { R_EAX_5:u32 R_EBX_6:u32 R_EDI_3:u32 R_ESP_1:u32} Ret +c @80492d9 (Addrset: @80492d9 @80492da @80492db @80492dc @80492dd ) [; mov %ebx,%eax; pop %ebx; pop %edi; ret ]
Printing Arithmetic gadgets: 0
Printing ArithmeticConst gadgets: 0
Printing Loadmem gadgets: 0
Printing Storemem gadgets: 0
Printing ArithmeticLoad gadgets: 0
Printing ArithmeticStore gadgets: 0
Printing SwitchStack gadgets: 1
SET: SwitchStack(R_ESP_1:u32 + 8) { R_EAX_5:u32 R_EBX_6:u32 R_EDI_3:u32 R_ESP_1:u32} Ret +c @80492d9 (Addrset: @80492d9 @80492da @80492db @80492dc @80492dd ) [; mov %ebx,%eax; pop %ebx; pop %edi; ret ]
Printing MemPivot gadgets: 0
Printing Syscall gadgets: 0
Printing Super gadgets: 0
The code at this address is mov %ebx,%eax; pop %ebx; pop %edi; ret.
Interestingly, Q figured out that it could load into %eax by simply
executing the gadget twice. This allows you to put a value into
%ebx during the first execution, and then move that value to %eax
during the second execution. This is fairly cute, and I don’t know if
I would have thought of the same trick myself.
Maybe it’s just me, but I am always surprised when automated systems
out-smart us. With respect to security, this means that we really
need provable and measurable defensive capabilities. The “I don’t see
any attacks” defense strategy is simply not good enough against a
sophisticated attacker. Just because we (as limited humans) cannot
see an attack against our system does not mean that an attacker, who
can create a sophisticated program to search for attacks, will not.
Warning: This blog post is not going to be useful to you unless you are trying to understand the pcmpistri instruction. It is not self-contained. See Section 4.1 of the Intel Manual for reference.
A while back I wrote a blog post about how bad the
documentation is for the x86 instruction pcmpistri. I wrote the previous blog post on pcmpistri as I was trying to implement the behavior of
pcmpistri only for the control byte 0xc.
Now I’m trying to add a more general implementation to BAP. This
involves reading and understanding the documentation, specifically focusing on the various aggregation modes that effectively control the behavior of pcmpistri. The problem
with the documentation is that it’s a literal translation of what the
processor is doing, i.e., a description of the circuit that implements
the instruction, rather than an abstract description of what’s going
on. A more abstract view is helpful when not implementing
hardware. In this blog post, I give pseudocode that computes the intres1 intermediate result variable for each of
the four aggregation modes.
I hope these are helpful in understanding the various aggregation
modes. Even though each one of these cases is simple, it was
difficult for me to get here from the documentation. However, you
should take these pseudocode algorithms with a grain of salt. I will update them as I find any problems, but I haven’t
tested these yet. Each pseudocode listing is a direct translation from my notes of the
Intel manual. I have also yet to formally demonstrate that these are
equivalent to the specifications in the documentation. I hope to
write a blogpost about how you can use BAP’s verification condition
algorithms to show such an equivalence.
Notation
r is the register operand, rm is the register or memory operand,
and u is the upper bound on the number of elements inside each
operand (i.e., 16 for byte-size elements, and 8 for word-size).
Pseudocode
EqualAny
EqualAny sets intres1[j] if rm[j] is a character listed in r.
12345678910111213141516
intres1=0;for(intj=0;j<u;j++){// Once the string ends, we cannot find more charactersif(rm[j]==0)break;for(inti=0;i<u;i++){// Once the character set ends, stop lookingif(r[i]==0)break;if(rm[j]==r[i]){// We found a match, move to the next character in stringintres1[j]=1;break;}}}
Ranges
Ranges sets intres1[j] if r[i] <= rm[j] <= r[i+1] for some even
index i. r is a list of ranges.
123456789101112131415
intres1=0;for(intj=0;j<u;j++){if(rm[j]==0)break;for(inti=0;i<u;i+=2){// XXX: Not sure if next line is correct// Intel Manual underspecifiesif(r[i]==0||r[i+1]==0){break;}// Check if rm[j] is in the rangeif(r[i]<=rm[j]&&rm[j]<=r[i+1]){intres1[j]=1;break;}}}
EqualEach
EqualEach sets intres1[j] iff rm[j] = r[j].
12345678910111213141516
boolrnull=0,rmnull=0;intres1=-1;for(inti=0;i<u;i++){if(r==0){rnull=1;}if(rm==0){rmnull=1;}if(rnull&&rmnull){break;}else// If exactly one string is nullif(rnull!=rmnull){intres1[i]=0;}else// If both strings are valid.if(rm[i]!=r[i]){intres[i]=0;}// Fall through: strings are valid and the same}
EqualOrdered
EqualOrdered sets intres1[j] iff the substring in r is present at
rm[j].
123456789101112
intres1=-1;for(intj=0;j<u;j++){for(inti=0,intk=j;i<u-j;k++,i++){// end of substringif(r[i]==0){break;}// the string ended before the substringelseif(rm[k]==0){intres1[j]=0;break;}// the string and substring differedelseif(r[i]!=rm[k]){intres1[j]=0;break;}}}
Musings
Ideally we’d be able to compute each intres1[j] independently, but
it doesn’t seem to be the case. break can be thought of as using
implied state, i.e., whether we executed break or not.
I’ve often noticed that hard problems are often found in many forms in
seemingly irrelevant projects. I ran into an interesting one the other
week. I am running some experiments that test verification conditions
(VCs), which are algorithms that produce a formula that can be tested
with a SMT solver to demonstrate some forms of program correctness.
VCs are a very useful technique right now because there are some
really great SMT solvers out there – we often use STP, Yices,
Boolector, Z3, and CVC3.
You might be familiar with a very common VC, Forward Symbolic
Execution (FSE). Dijkstra also created his own VC, called Weakest
Precondition (WP), which is generally defined on a language called the
Guarded Command Language (GCL). The specifics of the GCL do not
matter for this blog post. What matters is that it is a structured
programming language; that is, it contains no jumps or goto
statements. The only control flow operators are the sequence
operator, and a conditional operator. Many followup algorithms for WP
have followed in the footsteps of Dijkstra and defined their
algorithms to work on the GCL.
The problem is that the GCL is not a real programming language, and so
we must first convert programs to GCL to run these algorithms on
them. Of course, for me, this means converting BAP programs to GCL.
It turns out that my adviser solved this problem while working on his
PhD. His dissertation gives an algorithm that visits a program in CFG
form in reverse topological order. When visiting a conditional branch
node n that has
two successors s1 and s2, the GCL programs gcl1 and gcl2 are
computed from s1 and s2 (don’t worry about the details). gcl1
and gcl2 are split into three parts: a common suffix, and a prefix
for gcl1 and gcl2 that is not shared. This is then converted to
(if (e) gclprefix1 else gclprefix2); suffix. The idea is to avoid
duplicating nodes in the GCL as much as possible.
The problem I ran into was when I started looking at large programs,
the GCL size was growing exponentially. After looking at some of the
examples, I realized this was a problem I had seen before! The above
algorithm is actually performing structural analysis: it is taking an
unstructured program (think of a CFG) and trying to give it structure
in the form of if-then-else or sequences.
A few months ago I was working on a more general structural analysis
algorithm. One interesting thing we found is that the short-circuit
behavior from high-level languages causes unstructured CFGs at the
binary level. For instance, the program:
1234
intf(intx,inty){if(x||y){return3;}return-1;}
creates the following CFG:
Notice that BB_6 and BB_7 are reachable from BB_5 but not dominated by
it; this is not good for structural analysis!
The high-level point of this post is that many hard problems are
related in some way. While working on the VCs, I had already
concluded that algorithms that avoid the GCL conversion process
entirely are preferable. I probably would not have taken the time to
figure out precisely why the GCL conversion had so much code
duplication in it, had I not remembered seeing a similar problem
before. It always pays to try to relate seemingly new hard problems
back to similar ones that you’ve solved or seen solved.
Right now, the engine is asked what the successors are for an
unresolved edge. All of the yucky details for maintaing the CFG and
such are hidden from the resolving code. There is also a VSA-based
engine, but it’s inefficient: VSA must be re-run from scratch every
time an edge must be resolved. I’m going to fix this, of course.
VSA-based lifting is neat because it allows lifting us weird malware
types of obfuscation, for instance:
1234
pushl$cooljmp*(%esp)cool:xor%eax,%eax
can be resolved:
Finally, here is an example of a switch being resolved:
The interesting thing here is that VSA resolved the indirect jump to
more than six destinations. Because the destination addresses are not
aligned, the strided interval representation is forced to
overapproximate. This is bad, but not a big deal in this case.
A more pressing issue is that (our implementation of) VSA’s abstract
stores (memory) is extremely slow. Balakrishnan says he uses
applicative dictionaries in his dissertation for this because it is
space efficient. Conveniently, OCaml’s Map module provides
applicative dictionaries. (Side note: I <3 OCaml.) However, abstract
interpretation often fails to prove termination of a loop. When this
occurs, any stack pointer being increased in the loop has its upper
bound widened to about 2^31. As soon as data is written to this
pointer, 2^31 maps are added to the abstract store. This takes a
while (minutes on a very fast computer), but as Balakrishnan notes, it
is space efficient. Unfortunately, even more slowdown occurs whenever
the meet operation takes place on two abstract stores: every
individual element (a value set) in both stores must be traversed.
There is no easy way to get the differences between two maps in the
OCaml Map module. (There is Set.difference, though.)
I see two possible solutions here.
Create an efficient abstract store data structure. This structure
would be strided-interval aware, e.g., it would not store 2^31
entries when writing 0 to [0, 2^31]. It would also be able to
identify differences in two structures very quickly. We might want
something like an interval tree.
Whenever a pointer value set gets “too big”, widen it to top. This
has the disadvantage of wiping out memory on that region. In the
first option, we would only wipe out any memory locations above the
lower bound of the pointer.
Coq and Isabelle/HOL are both “proof assistants” or “interactive
theorem provers”. Both systems allows one to model a theorem, and
then prove the theorem true. The resulting theorem is then checked,
typically by reducing the proof to a program that can be type checked.
Type checkers are relatively simple, and so we are confident that
these machine checked proofs are correct.
I’ve been reading Software Foundations, which is an
introduction to program semantics and verification in which everything
is modeled and proved in Coq. Remember doing those dreaded structural
induction program semantics proofs by hand? It’s a little bit more
satisfying when done in Coq, and sometimes is easier too. More
recently, I have been learning Isabelle/HOL. Technically, Isabelle is
a proof assistant that allows multiple logics to be built on top of
it, including HOL, or High Order Logic.
Unlike Isabelle, Coq only supports High Order Logic natively. Coq has
support for \forall and --> baked in to it. --> is used to
represent both entailment and logical implication. As a result, it’s
very easy to write down theorems, because there is generally only one
way to write them! Isabelle/HOL, being split up into Isabelle’s
meta-logic and HOL’s logic, is different. Isabelle has a notion of a
universal quantifier /\ and entailment ==> baked in. HOL then
models the \forall quantifier, and logical implication -->. Of
course, the two levels are closely related, and it is possible to
switch between them. However, when writing a theorem, it is often not
clear in which level quantification and entailment or implication
should be written.
In my first proofs, I errored on the side of HOL instead of the
metalogic, only to find that some of Isabelle’s utilities only work on
the metalogic level. For instance, there is no quick way to
instantiate p and q in \forall p q. P p q. There is a syntax,
however, for instantiating p and q in the meta-logic quantified
version. The ambiguity between logics is a very inelegant property of
Isabelle/HOL in my opinion.
Isabelle does have some nice features, though. It has a structured
proof language called Isar. The idea is to allow Isabelle proofs to
look like real, human proofs. (In contrast, non-structural mechanized
proofs are just a series of tactics, which do not explain why a
theorem is true.) Here’s a simple example:
123456789
case (Assert bexp)
assume eq: "bval p st = bval q st"
show ?case
proof -
have "bval (fse (Assert bexp) p) st = bval (And p bexp) st" by simp
also from eq have "... = bval (And q bexp) st" by (rule and_equiv)
also have "... = bval (fse (Assert bexp) q) st" by simp
finally show "?thesis" .
qed
I bet you can figure out what’s going on, even though you don’t know the syntax.
My last observation about Isabelle/HOL and Coq has to do with their
unspoken strategies. Isabelle/HOL seems to be designed to make
extensive use of simplification rules. Indeed the tutorial
essentially says to prove something, you should write your theorem,
try to prove it automatically, and if that fails, add a simplification
lemma and repeat! This is nice when it works. However, manipulating
rules manually is difficult in my opinion, although that could be
because I’m a novice user. Manually manipulating rules in Coq is much
easier; the design of tactics just seems to allow me to do what I want
more naturally. On the other hand, I’ve been using Coq for longer.
In conclusion, Coq and Isabelle/HOL are both interesting tools, and
both can probably accomplish what you want. The differences are
subtle, and the best way to get a feel for them is to learn them! I
recommend Software Foundations for Coq, and the
tutorial
for Isabelle/HOL.